

前言: 這一篇技術文章我原本是發表於 2007 年二月...當初我還在某IC 設計公司。
所整理的一篇關於一般傳統8 bits MCU 的有關中斷(interrupt)觀念。
後來離開後~人家希望我拿掉一切有關該公司相關產品的內容...
當然啊,這幾年來32 bits MCU 蓬勃發展,尤其ARM 在今年三月發表了Cortex-M0+
之後,讓我們這些搞系統的眼睛為之一亮 ,這一棵擺明了衝著傳統8 bits MCU 市場而來的!
到底最後在價格上是否真的可以與傳統8 bits MCU 一較長短外?!我想至少他在
MCU 基本的架構上也算是明顯勝出了!這也的確讓我們看出ARM 的企圖心。
關於Cortex-M0+ 的詳細解說,我們改天再聊,那就先把我當年寫的文章重新整理一下
細述如下...(至於關於原來文中所出現原本該公司的東西,您就不用太刻意...
我只是拿來簡單示意解說一下...說真的~過了這麼多年我也不解原本公司產品現況,
我也不是針對該公司產品。相關人士就不用太操心了!)
---------------
我們來講一些在單晶片應用中常用的中斷觀念,其實,這也是跟USB的一些應用也蠻
有關係的。
因為在版主的相關USB文章一直提到有關USB Controller 都是利用中斷觀念來完成
一些USB Protocol 的東西。那這些我們所熟悉的中斷又有哪些值得我們探討的呢?!
以下圖的那條藍色訊號來看一個應用:譬如這一條外部訊號線是約 1uSec 的波寬,
我們有可能用單晶片的中斷向量程式,在此波寬中Toggle 出一個幾近同步的脈波寬嗎?!
我們都知道:反正只要外部中斷一發生,我的應用程式會馬上跳到中斷向量位置去執行
相關的中斷服務程式,但您可曾去量過:當您跳進中斷向量程式中時,您的程式執行點
跟這個"外部中斷"訊號有『同步』嗎?這張圖的進一步解說,我們稍後再回頭來解讀!
我們先來檢視一般8051 或PIC 的相關技術資料。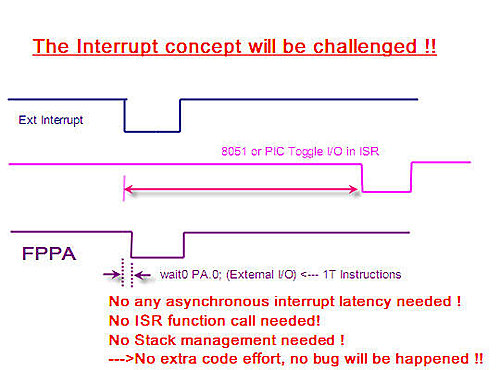
下圖是一般8051 的技術文件,這種8051 是可以不管他是幾個T 的8051 (管他是12T
或4T的8051 ,他的道理是一樣的!)我已經把重點用紅筆畫出來了!最快就是
5 Instructions ~當然,您是4T的8051 的話,那就代表您會需要 20 T 才會進入中斷!
進入中斷還不包括您還要Push/pop 一大堆stack 喔!而且,萬一您的中斷優先權不夠的話,
您的中斷程式還是得再等一下子呢!
---- 所以,您會看到一些號稱用8051 寫的一些所謂 RTOS(Real Time OS) 都會標榜他們
的OS的Interrupt Latency 是< 20T 或是15 T 以內的!但實際上,他們都會有先天上的
所謂Interrupt Latency !
所以,我們用8051 為核心的USB Controller 也會有存在類似的問題,只不過,
人家用一些硬體的東西幫您擋掉一些USB 通訊介面的其他與韌體較無關的中斷訊號!
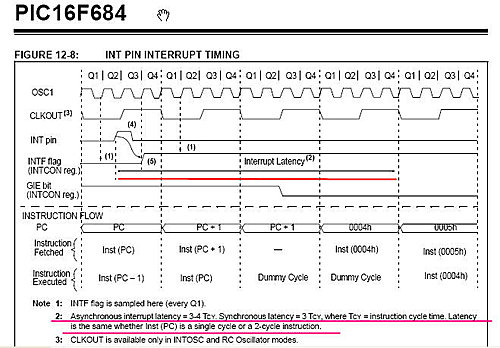
那RISC 架構的Microchip PIC 就會比較好嗎?!下圖為PIC16F684 的技術資料,
我也把重點給Highlight 出來了。他的外部中斷訊號也需要3~4T的同步時間,這是在
硬體設計上,先天的宿命,您總不該訊號一進來就把人家的指令馬上停掉吧~
這一點觀念對於那種CISC的8051 會更嚴重,為什麼?萬一您中斷訊號一來,
您剛好正執行到MUL這種號稱需要12T以上的指令集,您的中斷訊號總得要等這個
指令完成吧!這一點在上圖的最後那幾句話也有點出這個問題。
那PIC 會比較好嗎?哈~哈~很不幸,因為在PIC12/PIC16 系列來說:
他們只有一個中斷向量位置(04h)而已,至於是哪一種中斷產生中斷呢?!
您的中斷向量程式還是得一一檢查一下中斷旗標才會知道的~
這一點就是我用粉紅色的線條標示出來,所以,這些判斷程式也無形中造成另一種無形,
而且還不可預期長長短短的Interrupt Latency 呢!

下圖就是用顯然易見的圖示來說明這種先天宿命的Interrupt Latency !
他只是幫您跳到04h的中斷向量位置而已呢!還沒幫您估您程式中的中斷旗標判斷的時間呢。
所以,我們就回到最上面的那張圖來看:當您程式收到外部中斷訊號時,
其實,您所能及時反應時間,都已經無形中『偏離』這個中斷訊號很遠了!
而且,還很討厭的是:中斷常常會讓我們的正常的應用程式給打亂(廢話,要不然怎會叫
『中斷服務程式』呢?!)~往往一些容易出錯或系統不穩定因素都是
這些難以預期『中斷服務程式』給造成的。要不然就要在中斷服務程式中,
拼命的利用Stack 來儲存原來正常程式的狀態(包括旗標,變數或甚至執行程式點!),
也會造成Stack 空間的浪費,一個不小心還會來個 Stack Overflow ~
這個名詞大家都應該不陌生!
----
其實在上圖說明中:我們點出了RISC MCU 的基本Pipeline 的觀念...Pipeline
這個名詞您也會在ARM 的許多產品說明上聽到,我們簡單用下圖說明:

當我們一般MCU在執行我們的程式碼時,他的基本動作就依循上圖的Pipeline 方式執行的...
第一個動作叫: Instruction Fetch...就是把程式指令抓進中央處理單元...
第二個動作就是做 Instruction Decoder 指令解碼...當然這個Clock cycle ...原本對外的
Fetch 電路又可以做Pre-Fetch 的動作~以達到同步運行的動作
第三個動作就是Execution...就是執行程式指令...接下兩個MEM (Memory Access )
或是WriteBack Register...就得看您的指令內容是否與其他周邊的Memory 或Register有關!
所以要提升MCU 的執行速率,一種就是直接提高這些Clock Cycle...最快!
譬如從原來的12 MHz 提高到24 Mhz 或更高...但這也有其限制的,譬如:有些
Fetch 指令要從OTP 中取出,或是要寫回Static Memory...可能因為這些裝置的速度跟不上
中央處理單元...(您就想像一下,有時寫Flash 也要Delay 一下的道理是一樣的!)
所以...有些指令就不可能在一個T 的Cycle 內完成...就是要等!也就是為什麼有些指令是1T
有些是2T ...甚是像乘法或除法因為要動用到比較多的邏輯閘...速度就會受限!
另一種就是把Pipeline 做最佳化...因為增加Pipeline 有時可以提升速度,但也會增加複雜度
而使效能未必提升,甚至增加了IC 邏輯閘數量---增加成本。
-----
好了~我們再回到中斷的觀念...
從以上的解說發現:不管您是用內部Timer 中斷做出一個分時多工的作業系統,
或是針對一些外部硬體中斷做出一些程式對策執行指令時,就難免就會產生中斷問題,
當您要處理的中斷越來越多...(當然現在MCU 要求功能一大堆的...當然中斷就會變得
很多種!很複雜...USB 的算簡單的...萬一有什麼ADC 中斷~I2C中斷...外加SPI...等)。
您就會發現:您的MCU 大概什麼運算式都不用作了。就是一直處理中斷就好了。
而中斷在程式裡就是很討厭...一下子跳進來~一下子又跳出去...跳來跳去也沒關係,
更討厭的是每跳一次就要搬一次Stack ...記住從哪裡?要回到哪裡去?!...
萬一要儲存的資料很多,Stack 不夠深怎麼辦....出了Bug 又很難抓!
這就一方面考驗著系統韌體工程師的功力,當然他也會造成整個MCU執行效能的瓶頸。
尤其我們碰到上述那一種當中斷發生時,剛好又有另一個中斷進來~這一種俗稱
Nested Interrupt(巢狀中斷時)...整個Stack 或程式邏輯會大亂...您也不要鐵齒,
覺得自己寫程式不會這麼倒楣,但是中斷就是意料之外,您怎麼保證不會撞在一起?
------
所以我想現在MCU 要提升執行效能外,除了把指令寬度或處理資料長度放寬為
32 bits 之外,當然也可以提升每一個指令的效能...譬如調整Pipeline ,做到最佳化
讓所有指令幾乎在一個T (system Clock) 完成。再來就是提升操作的system clock...
但這些方法大概您想得到~別人也可以想得到,尤其最簡單的提升提升操作的
system clock...這也需要IC 晶圓製程技術的配合,譬如: 45nm 的間隙鐵定比 90nm
的間隙窄,以短跑速度一定來說:當然可以瞬間達陣...耗電也比較低!
---
另一種大概就得要從中斷的處理能力來看:這一點大家可以看到ARM 在Cortex-M 的
努力:http://www.arm.com/products/processors/cortex-m/cortex-m0.php
中的那一項Technology :他就是用硬體架構去強化軟體中斷在Stack push/pop
之間的間距(latency)。
第一種:兩個中斷瞬間同時產生:

第二個中斷很明顯的優先權沒有第一個高,他就得必須等第一個中斷完成後,
才可以接著執行,但很明顯對硬體來說:其實他也知道有另一個中斷Pending 在後面,
所以他們就用硬體強化(簡化)軟體上要做Stack Push/pop的時間,去有效縮短中斷
所產生的Latency...
-----------------
第二種是:當一個中斷程式執行中,剛好有另一個優先權的中斷又產生...

這一種最可憐,中斷程式當場被另一個中斷服務程式硬生生的搶走,
傳統的MCU 就得要多準備一組Stack 來處理這一種巢狀結構的中斷,當然啊...
ARM 宣稱他用一種特殊的仲裁機制來處理這一個後面進來搶的中斷服務程式。
也可以有效的縮短這一部份所產生的Latency---不用說這肯定得用硬體做的!
----------------------
第三種就是一個中斷緊接著另一個即將完成的中斷之後...應該蠻常見的!
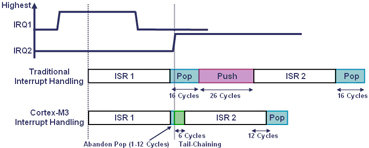
這也是應該最容易處理~ ARM 說他把原本的第一個中斷要做的pop 就順便跟第二個中斷的
push 動作(其實就是在Stack 中搬來搬去的...)做一個整合處理以縮短兩者之間的
跳來跳去的麻煩----當然硬體機制一定要做得很好,否則不小心會隨時掛點的...
但至少ARM 應該有花一點心思在這方的考量吧!
---------------------------------------------------------------------------
其實我們很簡單的帶了一下一些基本MCU 的中斷觀念.... 其實這些觀念在寫韌體程式中
真的很重要,尤其像您碰到USB 這些系統應用時,更需要瞭解!因為這些中斷的
Latency 對於您USB 傳輸的Performance 影響很大。
另外,我們也很高興看到新一代的MCU (其實ARM Cortex-M0+已經算是效能有目共睹
新一世代MCU...)他不只純粹用32 bits 來擊敗一些傳統MCU 外,他在許多架構的調整上
也做了很多努力....對我來說:或許有機會連我也想試試看。
畢竟我們系統搞了這麼久了~我們老是在一些傳統的8 /16/32 bits 基本架構的MCU 裡
被嚴重的限制了許多系統應用的瓶頸,看來ARM 的Cortex-M0+ 真的是有備而來的!
到底他的價格可以如何壓迫傳統 8 bits MCU 市場?!就讓我們拭目以待吧!
沒有留言:
張貼留言